토큰(Token)과 컨텍스트 윈도우(Context Window)
생성형 AI는 글을 읽는 것처럼 보이지만 실제로는 숫자를 계산합니다. 우리가 입력한 문장은 먼저 일정한 단위로 잘게 나뉘고, 그 조각이 숫자로 변환된 뒤, 다음에 올 내용을 확률적으로 예측합니다. 이때 사용하는 계산 단위가 토큰(Token)이고, 모델이 한 번에 참고할 수 있는 최대 범위가 컨텍스트 윈도우(Context Window)입니다.
토큰은 무엇인가요?
토큰은 모델이 텍스트를 처리하는 기본 계산 단위입니다. 사람에게는 단어처럼 보이지만, 실제로는 더 잘게 나뉠 수 있습니다.
예를 들어 다음 문장을 보겠습니다.
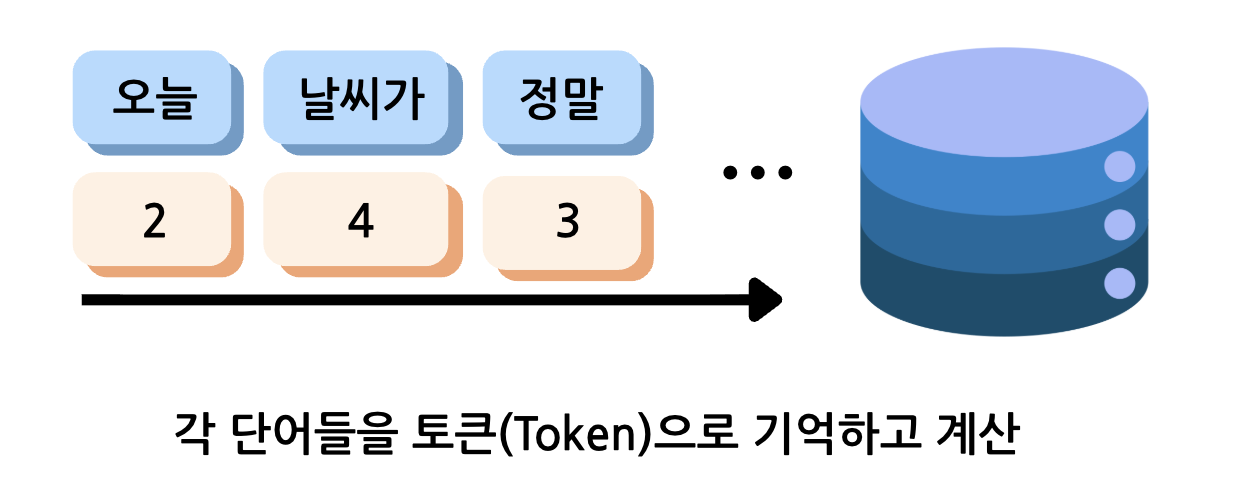
오늘 날씨가 정말 좋다.
사람은 다섯 단어로 인식할 수 있지만, 모델 내부에서는 다음처럼 나뉠 수 있습니다.
[오늘] [날씨] [가] [정말] [좋] [다] [.]
이 조각 하나하나가 토큰이 됩니다. 이후 각 토큰은 숫자로 바뀌고, 모델은 이 숫자들의 관계를 계산해 다음에 올 토큰을 예측합니다. 문장 생성은 단어를 통째로 꺼내는 작업이 아니라, 토큰을 하나씩 이어 붙이는 계산 과정입니다.
왜 단어 수와 토큰 수는 다를까요?
토큰은 단어 수와 정확히 일치하지 않습니다. 같은 길이의 문장이라도 토큰 수는 달라질 수 있습니다.
영어 단어를 예로 들어 보겠습니다.
unbelievable
이 단어는 내부에서 다음처럼 나뉠 수 있습니다.
[un] [believ] [able]
한국어에서도 비슷합니다.
했습니다 → [했] [습니다]
조사나 어미가 분리되어 계산되기 때문에 토큰 수가 늘어납니다. 그래서 사람이 느끼는 문장 길이와 모델이 계산하는 부담은 다를 수 있습니다. 모델은 글자 수가 아니라 토큰 수를 기준으로 계산량을 판단합니다.
대략적인 감각으로는 영어 1,000단어가 약 1,200~1,500토큰 정도가 됩니다. 한국어는 형태 분해 특성 때문에 더 많아질 수 있습니다.
컨텍스트 윈도우는 무엇인가요?
컨텍스트 윈도우는 모델이 한 번에 참고할 수 있는 최대 토큰 수입니다. 질문, 이전 대화, 시스템 지시문, 모델의 답변까지 모두 이 범위 안에 포함됩니다.
예를 들어 컨텍스트가 8,000토큰인 모델을 사용한다고 가정해 보겠습니다. 이미 입력된 대화가 7,500토큰이라면, 모델은 남은 500토큰 안에서만 답변을 생성할 수 있습니다. 이 범위를 넘으면 가장 오래된 내용부터 잘려 나가거나 무시됩니다.
이 때문에 긴 대화에서는 다음과 같은 일이 발생합니다.
- 초반에 정한 조건이 사라진다
- 이미 합의한 형식이 깨진다
- 앞에서 설명한 내용을 다시 묻는다
이는 이해력이 부족해서가 아니라, 참고 가능한 범위를 초과했기 때문입니다.
긴 문서를 다룰 때는 어떤 일이 생기나요?
보고서나 논문처럼 긴 문서를 한 번에 입력하면, 전체 내용이 컨텍스트 안에 다 들어가지 않을 수 있습니다. 이 경우 모델은 일부만 참고해 요약을 생성합니다. 그래서 앞부분 중심의 요약이 나오거나, 세부 내용이 빠질 수 있습니다.
컨텍스트가 긴 모델일수록 더 많은 내용을 동시에 처리할 수 있지만, 무한하지는 않습니다. 계산 범위에는 항상 제한이 있습니다.
토큰과 비용은 어떤 관계가 있나요?
많은 AI 서비스는 입력 토큰과 출력 토큰 수를 기준으로 비용을 계산합니다. 질문이 길어질수록, 답변이 길어질수록 비용이 증가합니다. 반복되는 문장이나 불필요한 배경 설명은 그대로 계산량으로 이어집니다.
효율적으로 사용하려면 입력을 구조화하는 것이 중요합니다.
예를 들어 다음과 같은 요청은 토큰을 많이 사용합니다.
제가 지금 보고서를 작성하려고 합니다.
주제는 인공지능 윤리에 관한 것이고,
분량은 5페이지 정도이고,
너무 딱딱하지 않게 작성해 주셨으면 좋겠고,
위험성과 장점, 미래 전망까지 포함해 주세요.
같은 내용을 더 간결하게 표현할 수 있습니다.
주제: 인공지능 윤리
분량: 5페이지
포함 내용: 위험성, 장점, 미래 전망
톤: 학술적이되 과도하게 딱딱하지 않게
긴 문서를 다룰 때도 마찬가지입니다. 60페이지를 한 번에 넣기보다, 여러 부분으로 나누어 요약한 뒤 마지막에 통합하는 방식이 더 안정적입니다.
1~10페이지 요약
11~20페이지 요약
위 요약들을 통합해 전체 3페이지 요약 작성
이처럼 단계적으로 처리하면 컨텍스트를 넘지 않으면서도 전체 내용을 반영할 수 있습니다.